Deep Neural Network Probabilistic Decoder for Stabilizer Codes
Stefan Krastanov, Liang Jiang
Departments of Applied Physics and Physics, Yale Quantum Institute, Yale University, New Haven, Connecticut 06520, USA
Error Correcting Codes and their Decoding
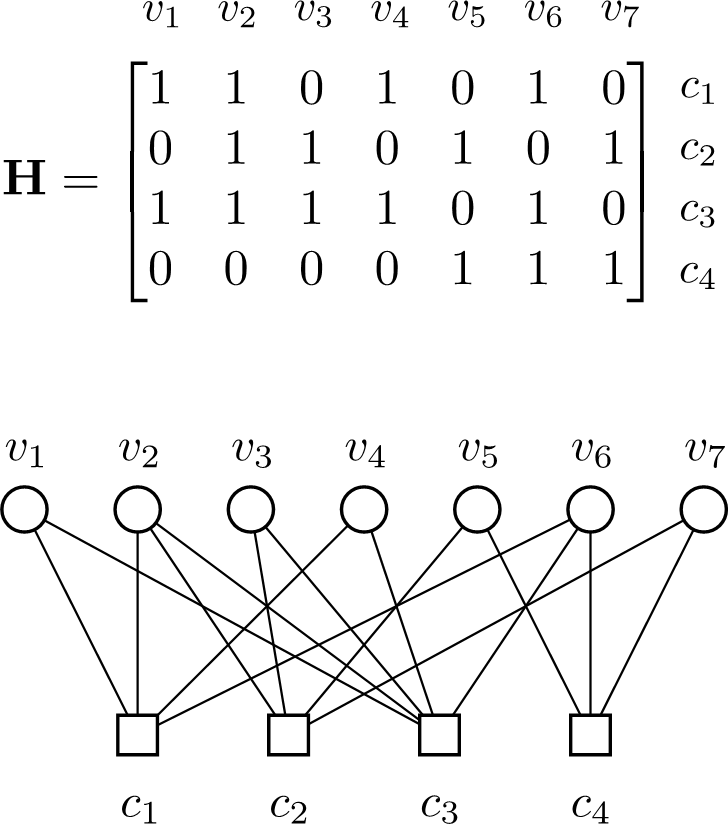
Error correcting codes (ECCs) encode a number of logical bits (or qubits) in a larger number of physical bits/qubits, by employing some form of redundancy in order to ensure that the encoded information can be decoded, even if errors have occurred.
A common way to provide the redundancy is the use a system of linear constrains (i.e. constraining the parity) on the physical qubits, as used in stabilizer codes (or their classical counterpart - linear codes). These constraints are frequently represented as a matrix equation, or equivalently as the corresponding graph connecting each "check" $c_i$ (constraint) to its "variables" $v_i$ (qubits whose parity is constrained). Examples for a small code are given in the figure.
A substantial challenge presents itself when one attempts to decode a code after an error has occurred. In general, this is an infeasible NP-complete problem, but in many cases the particular code would have some additional structure that permits the creation of a smart efficient decoding algorithm.
We present a method of creating a decoder for any stabilizer code, by training a neural network to invert the syndrome-to-error map for a given error model. We evaluate the performance of our decoder when applied to the Toric Code.
Example: The Toric Code and its MWPM Decoder

We will use the Toric code as a benchmark for our otherwise general protocol. In the Toric code the physical qubits are laid out in a lattice, and the parity checks act on cells of the lattice. This structure permits interpreting the non-trivial stabilizer measurements as particle-antiparticle pairs and the errors as strings connecting those pairs. In that interpretation decoding becomes a problem of matching and annihilating those pairs, for instance by minimizing the total length of the strings as done by Minimal Weight Perfect Matching (MWPM).
Neural Networks 101
Neural Networks are exceedingly good at fitting high-dimensional nonlinear functions to given training data
The function to be "learned" is expressed as a network of "neurons". The function is parametrized by the strengths of the connections between neurons. Those parameters are updated through gradient descent until the function matches as closely as possible the given training dataset.
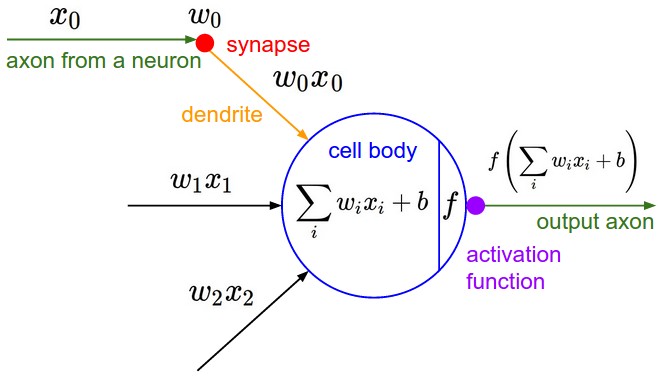
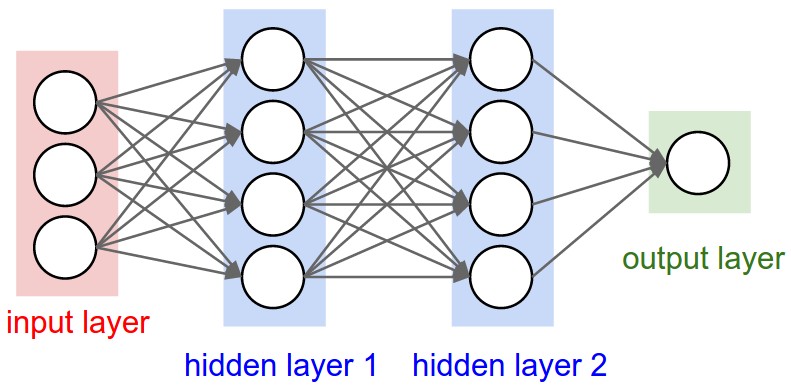
The Neural Network Quantum Error Correcting Code Decoder

The goal of any decoder is for a given syndrome measurement $s$ to deduce the most probable error $e$ that caused it. In our approach, for a given code and error model, we generate a large sample of errors and compute the corresponding syndromes. Then we use that data to train a neural network to do the mapping from $s$ to $e$, i.e. to decode the syndrome. The training is done through stochastic gradient descent that updates the parameters of the neural network so that the difference between the predicted error and the actual error is minimized. An important caveat is the need to interpret the output of the neural network as a probability distribution - it is not a discrete yes/no answer, rather a probability that an error occurred given the syndrome.
Note: Efficient Sampling from the Neural Network

For a given syndrome $s$, the network's output $E$ is evaluated and interpreted as a list of probabilities for a qubit error to have happened. An array $e$ (whether an error occurred) is sampled from $E$. We check whether the guess $e$ produces the same syndrome as the initially given one. If not, we resample only the qubits taking part in the stabilizer measurement corresponding to the incorrect elements of the syndrome.

After a set number of "give up" iterations, we consider this a detected, but uncorrected error. The performance with respect to this parameter is presented in the figure. For codes of more than 200 qubits, this protocol can become impractical.
Benchmark: Comparing to Other Decoders
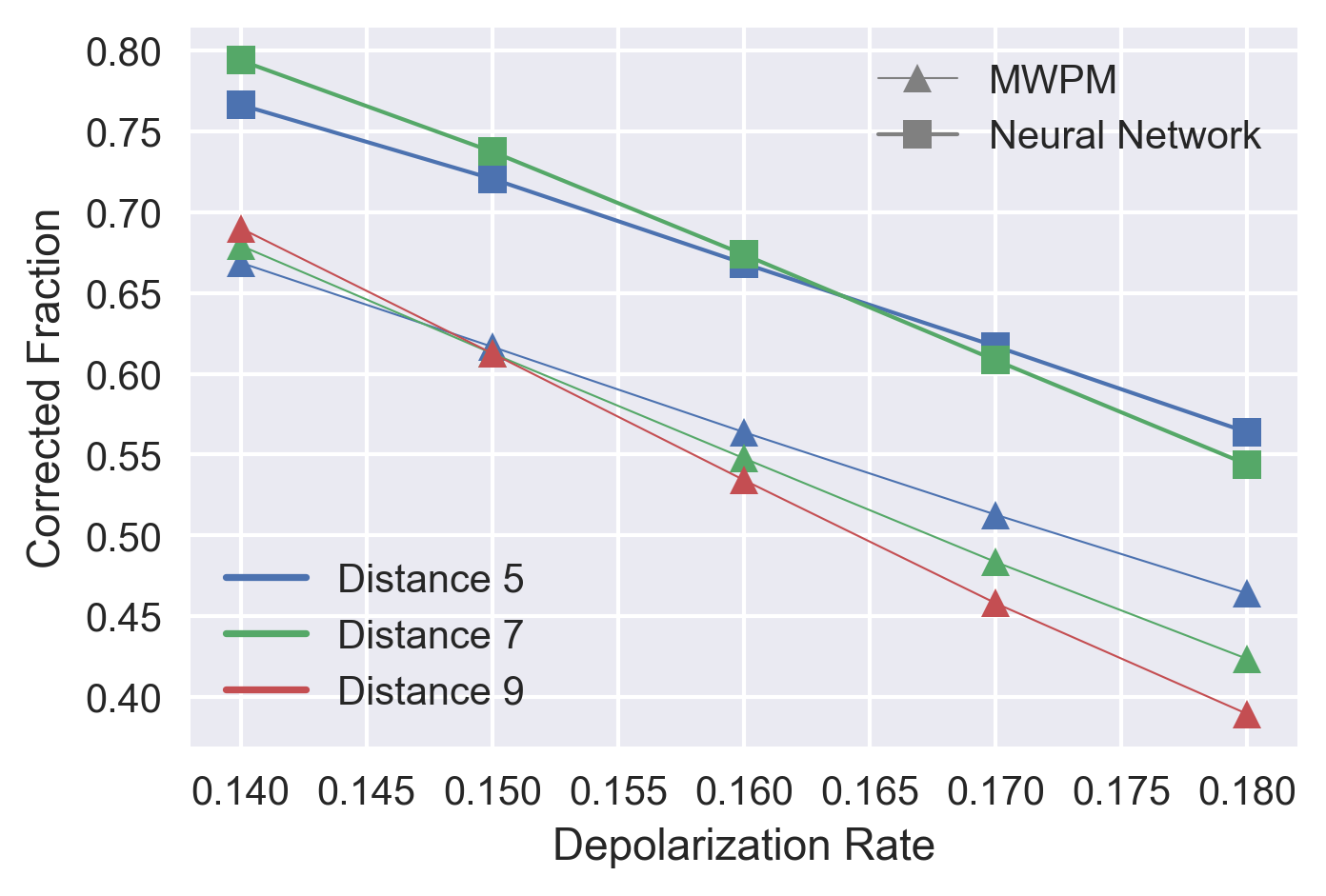
Our neural decoder's threshold (16.4%) compares favorably to renormalization group decoders[2] (threshold of 15.2%) and significantly outperforms MWPM. To our knowledge only a renormalization group decoder enhanced by a sparse code decoder[2] reaches a similar threshold (16.4%). All of these decoders have been hand-crafted for the Toric Code, while ours has no knowledge of it in its design and can be applied to other codes. There are a number of other recent attempts to employ neural networks as decoders, notably[3], but they have been unable to outperform known decoders.
Conclusions and Outlook
Our architecture already provides a practical high-fidelity decoder for Toric codes of less than 200 qubits, outperforming most alternatives. The most exciting developments in the near future would be, on one hand the use of a more advanced sampling algorithm in order to scale to bigger codes, probably employing recurrent neural nets, and on the other, applying this architecture to promising LDPC codes that do not yet have any known decoders.
References
For our neural net architecture: Deep Neural Network Probabilistic Decoder for Stabilizer Codes, Scientific Reports, 2017
[1]: Karpathy, "CS231n: Convolutional Neural Networks for Visual Recognition", 2015
[2]: Duclos-Cianci, Poulin, "Fast decoders for topological quantum codes", PRL, 2010
[3]: Torlai, Melko, "Neural Decoder for Topological Codes", PRL, 2017